
Les bases de la variation héréditaire, première partie
Comment les organismes se reproduisent-ils « selon leur espèce » (pour emprunter le langage de la Genèse) ? Cette question existe depuis bien longtemps en biologie. Une question proche naît de l’observation selon laquelle à l’intérieur d’une « espèce », tous les individus ne sont pas les mêmes – la variation existe au sein même de populations de la même espèce. Pendant de nombreuses années, le mécanisme qui pouvait expliquer la constance observée des espèces (la reproduction fidèle de la forme d’un organisme) et la variation observée (tous les membres d’une espèce ne sont pas identiques), sont restées mystérieuses. Afin d’éclairer ces problèmes importants pour la biologie évolutive, nous devons prendre le temps d’explorer les composantes du fonctionnement de deux molécules biologiques importantes, et de leur rapport l’un à l’autre : l’acide désoxyribonucléique (ADN) et la protéine.
(Article original ici)
Génétique moléculaire 101 : les protéines et l’ADN
Vous serez peut-être surpris d’apprendre que les premiers travaux qui ont exploré la base moléculaire de la génétique ont favorisé les protéines en tant que molécules héréditaires au lieu de l’ADN. On supposait que ce qui agissait en tant que molécule héréditaire serait large et complexe, et les protéines répondaient aux deux caractéristiques. Une protéine peut être très longue, puisqu’elle est un polymère composé de plus petits éléments(les monomères) : les acides aminés. Nous pouvons utiliser des briques de Lego pour illustrer cela. Une brique de Lego représente un acide aminé, et les briques fixées ensemble représentent une protéine. Comme les Lego de notre analogie, les acides aminés ont des caractéristiques communes qui leur permettent de se fixer ensemble en une longue chaîne. Ils ont aussi des différences significatives, analogues aux différentes couleurs dans le diagramme; certains acides aminés sont hydrophobes (c’est-à-dire qu’ils sont repoussés par l’eau) et d’autres hydrophiles (c’est-à-dire attirés par l’eau). Certains sont gros et volumineux, d’autres sont petits par comparaison, et ainsi de suite. Contrairement aux briques rigides de notre analogie, les protéines sont merveilleusement flexibles, et se plient en forme tridimensionnelle, déterminée par les propriétés des acides aminés.
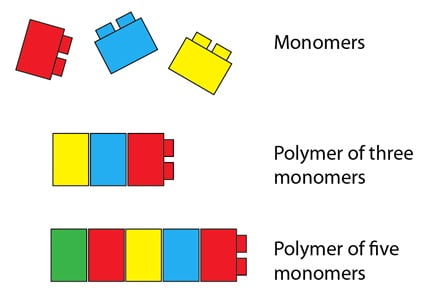
Il existe 20 acides aminés différents qui sont utilisés pour faire des protéines, et ils peuvent être combinés dans n’importe quelle ordre afin de produire une protéine avec des propriétés spécifiques – des propriétés qui naissent de la combinaison et de l’ordre spécifique des acides aminés, et de la forme finale qu’ils donnent à la protéine. Cette diversité des acides aminés signifie qu’il y a beaucoup, beaucoup de séquences de protéines possibles (et donc de formes et de fonctions possibles) – même un polymère composé de seulement deux monomères en longueur a 400 séquences possibles (c’est-à-dire 20², ou 20×20), et les protéines peuvent être longues de milliers d’acides aminés. C’est cette possibilité d’une complexité à grande échelle qui a suggéré que les protéines avaient peut-être assez de « capacité de stockage » pour porter l’information héréditaire et la transmettre à la génération suivante.
A la fin des années 1920, cependant, la recherche a commencé à s’éloigner des protéines pour se diriger vers l’ADN, comme molécule héréditaire. L’ADN, comme les protéines, est un polymère formé d’un ensemble de monomères (en l’occurrence, d’acides nucléiques). Au contraire des 20 monomères trouvés dans les protéines, l’ADN n’a que quatre monomères (les nucléotides) : des éléments qui sont abrégés A, C, G, et T. C’est pour cette raison que les chercheurs étaient initialement sceptiques qu’un polymère si « simple » puisse agir comme la source de l’information héréditaire.
Malgré ce scepticisme, des éléments en faveur de l’idée que l’ADN était en fait le support physique de l’information héréditaire ont continué à s’ajouter. Une fois qu’ils ont convaincu la majorité des scientifiques, il s’agissait de comprendre exactement comment l’ADN accomplissait cette remarquable tâche. Bientôt, il devint clair que comprendre la structure de l’ADN était crucial pour comprendre sa fonction, et plusieurs groupes de recherche sont entrés en compétition pour être les premiers à la déchiffrer. La détermination de la structure de l’ADN a en effet éclairé sa fonction. Bien qu’elle n’ait que quatre nucléotides, la structure de l’ADN a révélé la façon dont elle pouvait facilement se répliquer et transmettre de l’information : l’ADN n’est pas seulement un long polymère, c’est aussi un polymère qui peut spécifier sa propre réplication à travers des interactions entre ses nucléotides. Peut-être qu’une image rendrait l’explication plus claire. Imaginez que les briques ont maintenant des « partenaires » par lesquels elles sont attirées. Nous représenterons cette attraction, qui est un type de liaison chimique qu’on appelle la liaison hydrogène, avec un point noir. Les macromolécules « A » et « T » sont attirées par deux liaisons d’hydrogène, et les macromolécules « C » et « G » le sont par trois liaisons :
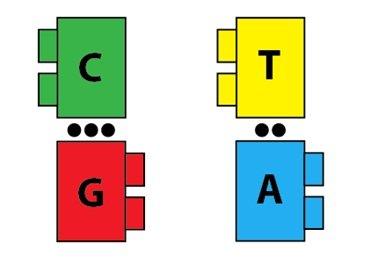
Les paires d’attraction entre les macromolécules sont importantes : elles autorisent un polymère d’ADN à agir comme un modèle pour un second polymère d’ADN complémentaire. Imaginez une séquence d’ADN comme celle qui suit :

Alors que le deuxième polymère d’ADN est fabriqué, des nucléotides sont sélectionnés, une à la fois, pour rejoindre son « partenaire » du premier polymère :
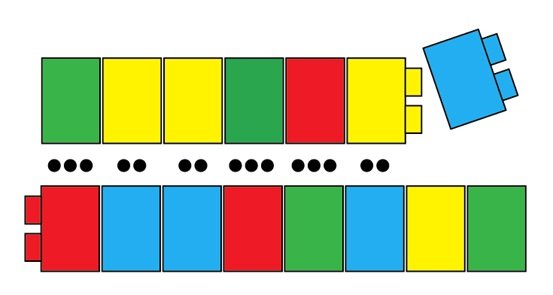
Ces deux polymères sont attachés par l’alignement de nombreuses liaisons hydrogène, et vous les connaissez probablement comme les deux brins de la double hélice de l’ADN :
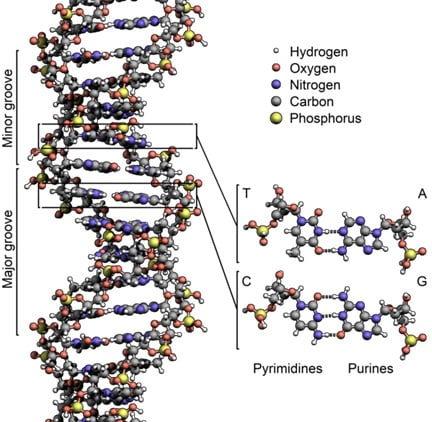
Source: https://en.wikipedia.org/wiki/File:DNA_Structure%2BKey%2BLabelled.pn_NoBB.png
Si ce modèle plus réaliste de l’ADN montre les détails précis de sa structure moléculaire, les caractéristiques importantes sont résumées par notre simple modèle de Lego. L’ADN est une paire de longs polymères qui peuvent être séparés et utilisés afin de faire de nouvelles copies, fidèles à l’original.
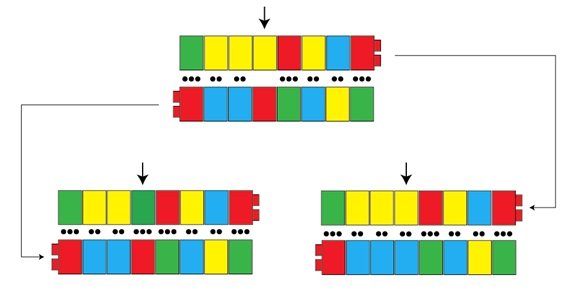
Alors que ces caractéristiques expliquent comment l’ADN est fidèlement copié, rappelez-vous que nous avons aussi besoin d’expliquer la variation. La variation, dans ses termes les plus simples, signifie que le processus de copie est parfois imparfait. Si l’ADN est bien la molécule héréditaire, et si la copie de l’ADN était à 100% exacte, alors la variation ne surviendrait jamais, et tous les petits seraient génétiquement identiques à leurs parents. [p1] La variation peut s’introduire de nombreuses manières pendant le processus de copie de l’ADN, et dans un billet futur, nous examinerons plusieurs d’entre elles. La première manière que nous considérerons ici passe par les « paires inappropriées» de nucléotides faites pendant la réplication. A une certaine fréquence (très basse), des nucléotides inappropriés sont rangées par paire. La flèche dans la figure ci-dessous montre une telle paire inappropriée, là où une macromolécule rouge (G) sur le brin du bas est incorrectement rejointe par une macromolécule jaune (T) quand le brin du haut est fabriqué. Lorsque cette série est répliquée, les brins du haut et du bas sont copiés, mais les partenaires appropriés pour chaque nucléotide sont trouvés cette fois. Il en résulte deux versions : une copie possède la paire originale C :G (sur la gauche), et l’autre possède une nouvelle variante, avec une paire A :T (sur la droite). Ce changement sera fidèlement copié à partir de là, puisque des copies plus récentes ne « savent » pas ce qu’était la séquence originale. Le résultat, c’est une nouvelle variante dans la population.
[p1]La recombinaison n’a pas été décrite. Je n’en parlerais pas ici !
Prises ensemble, les propriétés de l’ADN coïncident avec ce que l’on observe dans la nature : une reproduction fidèle de la forme, mais pas une reproduction parfaite de la forme. La constance et la variation héréditaire des populations biologiques retracent le fonctionnement de l’ADN.
Qu’en est-il des protéines ?
Si les propriétés de l’ADN font d’elle une grande molécule héréditaire (qui autorise pour autant la variation), l’ADN en tant que tel n’est pas capable d’assurer les fonctions quotidiennes dont l’organisme a besoin (fonctions d’enzyme, fonctions structurelles, etc…). Pour ces fonctions, la vaste diversité structurale des protéines est requise. Dans le prochain billet de cette série, nous verrons comment l’information héréditaire de l’ADN est transférée à la structure et fonction de la protéine, et comment la variation dans l’ADN peut causer de la variation à l’échelle de la protéine.
48 Articles pour la série :
- 01-L'évolution expliquée : Introduction
- 02-L'Evolution : Une théorie testée, pas une simple hypothèse !
- 03-Biogéographie
- 04-Une introduction à la variation, à la sélection naturelle et artificielle
- 05-Les chiens domestiques
- 06-Comment ça marche, la sélection naturelle ?
- 07-La sélection naturelle et le lignage humain.
- 08-Les bases de la variation héréditaire, première partie (Cet article)
- 09-Les bases de la variation héréditaire, deuxième partie.
- 10-De la variation à la spéciation (1)
- 11-De la variation à la spéciation (2)
- 12-De la variation à la spéciation 3
- 13-De la variation à la spéciation (4)
- 14-Les génomes sont comme des anciens textes (1)
- 15-Les génomes comparés aux textes anciens (2)
- 16-Les génomes comparés aux textes anciens (3): les origines de l'homme
- 17-Le génome comparé à un texte ancien (4)
- 18-Le génome comparé à un texte ancien (5): rattacher le tout ensemble.
- 19-Les arbres généalogiques des espèces, des gènes, et tri incomplet des lignées
- 20-Tri de lignage incomplet et taille d’une population ancestrale
- 21-Une introduction à l’homoplasie et à la convergence évolutive
- 22-Evolution convergente et homologie profonde.
- 23-Coévolution et la course à l’armement prédateur / proie
- 24-Le parasitisme, le mutualisme et la co-spéciation
- 25-Comprendre l’endosymbiose
- 26-La diversification cambrienne et la mise en place des plans d’organisation animaux. Première partie.
- 27-La diversification cambrienne et la mise en place des plans d’organisation animaux. 2e partie.
- 28-La mise en place des plans d’organisation des corps vertébrés, première partie.
- 29-La mise en place des plans d’organisation des corps vertébrés, deuxième partie.
- 30-La mise en place des plans d’organisation des vertébrés : Troisième partie.
- 31-La mise en place des plans d’organisation des vertébrés, quatrième partie.
- 32-Des reptiles aux mammifères.
- La révolution placentaire : deuxième partie.
- Du primate à l’humain, première partie.
- Du primate à l’humain, deuxième partie
- Du primate à l'humain (3)
- La paléontologie hominienne : une petite esquisse des preuves actuelles
- Devenir humain (1) : Eve mitochondriale et Adam Y-chromosomique
- Analogie entre évolution biologique et évolution du langage
- Devenir humain (3) : paléogénomiques et la toile emmêlée de la spéciation humaine
- 41-L’évolution, Partie 1: frontières scientifiques, abiogenèse et apologétique chrétienne
- 42-Aux frontières de l’évolution, Partie 2: l’abiogenèse et la question du naturalisme
- 43-Aux frontières de l’évolution, Partie 3 : l’hypothèse du monde à ARN
- 44-Aux frontières de l’évolution, partie 4 : Contingence versus convergence
- 45-Aux frontières de l’évolution, partie 5 : Contigence versus convergence dans l’expérience LTEE
- 46- L’évolution et le chrétien, première partie: Est-ce que l’évolution est un mécanisme sans but ?
- 47- L’évolution et le chrétien, deuxième partie: Une créature merveilleuse
- 48- L’évolution et le chrétien, partie 3 : Dire la vérité dans l’amour




{kind=link}